Why I built alt-markdown (instead of switching to HTML)
HTML over Markdown? That's a bit insecure

On the 8th of May, 2026, Anthropic published an article, "Using Claude Code: The Unreasonable Effectiveness of HTML". The author, Thariq Shihipar, a technical staff at the company, made some solid arguments for why you might want to switch from markdown to HTML for agent-human output. Some (especially vibe coders) agreed blindly, some agreed reluctantly or with caveats, and some flatly disagreed.
I would put myself in the second category. The nature of software development has evolved so much that we as humans cannot easily keep up with the hundreds or thousands of lines of code and other output agents can spin up in a short space of time.
And before you say "you're a developer, you should take your time to understand everything deeply", the history of technology has repeatedly shown that fortune favours speed over quality, at least in the early stages. Early Facebook, Twitter, AWS, and a hundred other startups are products of that very idea. However, there has to be a balance. When each of those projects grew big enough, the priority shifted slowly towards quality over speed. But I digress.
The point is , we need to synthesise dense information more and more today, and the blog post pushes for more graphical, visually stimulating output. With that, I completely agree. On the method, I strongly disagree.
For one, the token cost is high. A self-contained HTML artifact runs about 5.1x the Claude tokens of its markdown equivalent, and only about 15% of it is actual reading content. The rest is scaffolding the model has to generate, and then regenerate on every edit. Many tools even convert fetched HTML back into markdown before handing it to a model, precisely because the markdown is cheaper to process.
I measured this on the same one-page spec from the article, rendered four ways, counting tokens with Anthropic's own tokeniser:
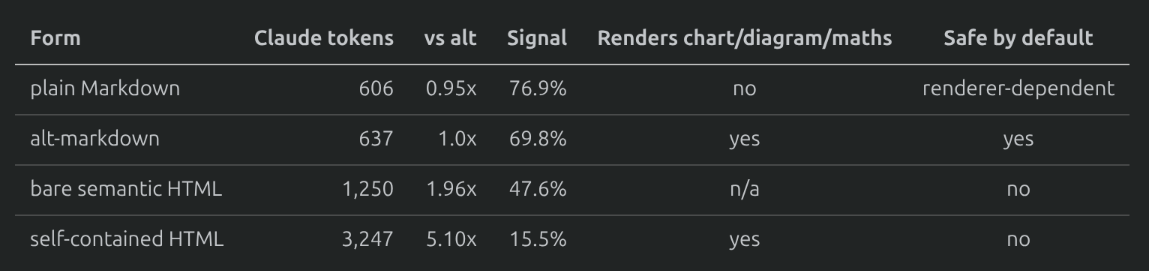
Alt-markdown (more on that later) costs about 5% more tokens than plain markdown, yet renders the charts, diagrams, and maths that plain markdown cannot, and stays safe by default. The HTML artifact pays 5x for the same content, and most of what you are paying for is the model describing a box, not the words inside it.
And while people use AI more and more for written content, plenty of us (myself included) would rather edit one or two lines in a markdown file directly than spend Opus tokens asking it to do the same, cause that feels like using a flamethrower to light a cigar.
But the most obvious issue to me was security. File systems, MCP tools, web browsers, and git history aren't the most trustworthy ingestion sources on earth, and they should not be treated as such. Web pages and MCP tools have repeatedly been turned into attack vectors. With self-contained HTML, an ingested string is live markup, so you're basically one payload away from a very bad day.
Even so, the article made a genuinely valid point: humans and AI increasingly need one shared representation that works well for both. So after some research, coding, and testing, I built alt-markdown.
The idea is simple: a (possibly over-engineered) superset of markdown that renders graphics and degrades gracefully to plain markdown, working for both old and new formats.
None of the properties I wanted were hard on their own, and most tools have one or two. What I could not find was a single thing that held all of them at once: a strict CommonMark superset, safe by default, no build step, and one core that runs the same in a browser and on the command line. So I wrote it.
It is one parser, written in Rust, compiled to WebAssembly for the browser and to a native binary for the command line, which is how a document is guaranteed to render the same in both. It passes all 652 examples in the CommonMark spec suite, so a plain markdown file is still a plain markdown file, and the extra capability is opt-in, one component at a time.
| Plain Markdown | Raw HTML | alt-markdown | |
|---|---|---|---|
| Rich tables, charts, diagrams | 🟨 | 🟩 | 🟩 |
| Reads as plain text | 🟩 | 🟥 | 🟩 |
| Safe by default | 🟨 | 🟥 | 🟩 |
| Easy for a person to review | 🟩 | 🟥 | 🟩 |
| Easy for a model to rewrite | 🟩 | 🟨 | 🟩 |
| Renders with no adoption | 🟥 | 🟩 | 🟨 |
| Arbitrary bespoke UI | 🟥 | 🟩 | 🟥 |
On the security point I cared about most, everything renders safe by construction. Text is escaped, link and image URLs are scheme-filtered, and the few things that could plausibly carry an exploit (a diagram or an embed), are confined to a sandboxed iframe that cannot reach the page around it. It also strips the Unicode bidirectional overrides behind the Trojan Source class, because if you are going to treat a document as untrusted, you may as well do it properly. An ingested string renders as inert text, not as markup waiting to run.
Now, of course, it is not all sunshine and rainbows. Security and convenience tend to have an inverse relationship, and I had to make trade-offs in a couple of places, balancing them out where needed.
For example, at the time of writing, alt-markdown does not support custom recomputation, one-off editing interfaces, or clickable prototypes. I dropped those because I don't yet have a solution I'm comfortable with.
Another trade-off is that of adoption. Like plain markdown, a .alt file needs a renderer, and AI models are already deeply familiar with HTML. HTML wins there. I'm hoping that changes in time, and working on it, but for now, it is a limitation.
If Thariq, or anyone at Anthropic, is open to comparing notes on the problems we're both circling, I would welcome the conversation. I think we are closer to agreeing than the framing suggests.
In the meantime, you do not have to take my word for any of it. Try it in your browser, no install: elementmerc.github.io/alt-markdown. Type on the left, watch it render on the right. The source is on GitHub.

